-
This is a document in progress ....
KI/SSS
The KI/SSS (Key Indicators / Strategic Support System) application is a CD-ROM based information system that has been published monthly since June of 1989, on CD-ROM since June of 1990. Currently nearly 400 replicates are sent to Federal Bureau of Prisons locations each month. Each disc contains information on all FBOP facilities from 1986 up through the prior month at monthly time points.
A browsable copy of the current user manual is here ... the version for printing is here
Why build KI/SSS?
KI/SSS was developed in the late 80's by the Federal Bureau of Prison's Office of Research and Evaluation (FBOP ORE). All development and production work was done entirely in-house, as an adjunct to other duties. The intended purpose was the provision of summarized data from mainframe sources via a simple, user controlled data retrieval system.
The initial impetus for the system was partially due to the volume of information requests from BOP facilities and administrators directed to ORE. This office was typically the only avenue for quick turnaround of ad-hoc summarizations of data associated with operational data systems on BOP mainframes. The operational databases were transaction oriented, with the individual inmate or staff person being the unit of organization. Existing user accessible systems dealt with live data at the individual level, and any summarizations were strictly against the current database configuration.
ORE was creating monthly snapshots of the bureau's data, which allowed comparisons across time points, as contextual information for program analyses. ORE also had information and resources that permitted access in ways the standard user accessible software could not. For these reasons, ORE felt compelled to provide the ad-hoc reporting services, even though it was often at the expense of personnel resouces for ongoing evaluation projects.
Whose bright idea was this?
William Saylor (aka 'Bo'), the current Assistant Director of the Office of Research, decided that the best way to reduce the burden of the ad-hoc reporting was to empower administrators with on demand access to reliable, reproducable reports. He had noted that there were often occasions in which questions arose about the validity of the information ORE provide when it was apparently in conflict with data delivered from different sources or at different points in time. Quite often, both information items were correct when viewed in context of their preparation and interpretations. The problem was that different definitions may have been used, or that different assumptions were made about the nature of the data collection mechanisms.
Bo was very fond of quoting "When a man has two watches, he never knows what time it really is." He felt that much of this confusion would be eliminated if a central clearing house was used for information items, so that definitions would be consistant and summarizations would be accomplished in a uniform fashion. He had also observed that most of the report requests involved an aggregation of information, both across organizational units and across time. Rather than redo such aggregations for each report, it would be a great resource saver to do the summarization once and retain it for any future report requests. This philosophy became the basis for Key Indicators, a centralized repository for summarized mainframe data elements.
Bo's initial thought was to make use of a library of SAS programs and macros that would be accessible via dialup connections to the DOJ mainframe. After some serious thought, he concluded that such a plan might be usable by professional analysts, but would probably be unusable by the typical administrator. PC's were just starting to become widespread, with increasing power and utility. The 286 machines had just hit the market but, combined with hard drive storage, Bo felt there was the potential for tremendous data retrieval and processing capacity. By eliminating the arcane element of mainframe access and processing, the task of providing information access directly to administrators could be greatly simplified.
My name is Schoeneck Howell (aka Nick). At the time Bo was putting together the plan to provide PC level access to BOP data, I was currently posted to the Federal Penitentiary at Marion, Illinois, the BOP "super max" facility. I had been transferred there to put together a PC based litigation support system. The system provided ready access to inmate behavior histories for US attorneys working on a conditions of confinement lawsuit. The PC based system included information elements from both mainframe sources and locally entered materials. (Historical note: 12 years later, that system was still in operation and has been transported to the US Penitentiary at Florence CO, the new BOP "super max" facility where it provides support to local administrators and case managers.)
A working system was in place and had been producing reports for both local consumption and court use. Bo described the project to me and I was very interested in contributing. It was decided that I would be transfered into the central office and become involved in the PC portion of the project.
For roughly six months I split my focus between PC user interface development issues for Key Indicators and the projects underway at Marion. During that period, I made monthly trips into DC to participate in the Key indicators development planning. My contribution was to be the nuts and bolts of the user interface and programmer support code.
What kind of data is this?
The Key Indicators datasets are summarizations of a month's worth of transactions for a BOP entity when dealing with transaction based systems. The month is defined as the period from the end of the last KI/SSS summarization through the last saturday of the month. (KI/SSS data sweeps are fairly massive, it is necessary to run them in conjunction with one of the pre-scheduled back off and restore reorganizations done for the live systems on weekends) For descriptive components, KI/SSS datasets are summarizations of end of month snapshots.
The lowest denominator for data is the institution mission level, formerly designated by Continuous Action File Institution Codes (CAFINST), and later by Defined Facility codes (DFCL). There are also aggregations to security level summation, regional summation and Bureau overall. Most recently, aggregations of mission functions have been added. We've been in the data warehouse and retrievals business since KI/SSS began!
What's in the datasets?
Key Indicator datasets originally consisted of data elements from SENTRY (the Bureau's online inmate information database, containing demografic and assignment information), CAF (Continous Action File, recording admissions and releases of inmates), JUNIPER (an extract of the Justice Department personnel records for the BOP), and IIS (Inmate Information System, recorded inmate personal history, education information, program participation, etc.), and Correctional Services Significant Incidents. Since that time, a number of new sources have been added, and some older sources replaced.
Current items include results from the annual administration of the Prison Social Climate Survey (PSCS), which solicits work environment attitudes from BOP employees, Inmate Administrative Remedies, inmate discipline, drug testing, and staff discipline.
Who can run this crazy thing?
KI/SSS was conceived of as a user driven, on demand report generator. The user would not be required to have any data processing skills, or physical access to a centralized system. The information system would provide pre-built retrieval options with pre-formatted text reports and graphics. The user would specify the time points desired, the locations to be reported on and these would be applied to the selected report template.
KI/SSS initially conceived of as a mainframe based application, but the advent of reasonably powerful PC's (based on the Intel 386 CPU) offered a much more accessible mechanism.
The Data Engine - PRODAS
In laying out the PC based Key Indicators, the decision was made to store and retrieve data using Conceptual Software's PRODAS package. PRODAS was selected because of three factors: 1) it was very syntax compatible with SAS (Statistical Analysis System), a package used by all ORE analysts for manipulation and analysis of mainframe information; 2) it offered indexed datasets for fast direct access; and 3) it was available as a straight license for a reasonable one time fee (not an annual lease like PC SAS, which was virtually impossible to keep current given the combination the BOP procurement office and the SAS business office).
The User Interface
Some effort was made to produce a pilot version of KI/SSS using the menu capabilities of PRODAS, but the results were too kludgey and arcane. It was clear that an alternative approach was necessary. The first practical user interface for KI/SSS was based on simple text windowing techniques implemented under Borland's Turbo Pascal(initially TP vers. 3.0). It was labeled KI/SSS version 1.0 (Prototype)
Conceptual Software provided enough information about the inner structure of their data format that TP programs could be written to read, create and modify PRODAS datasets. This permitted a seamless interaction between user interface and PRODAS interpreter sessions.
The user interface initially consisted of three parts:
1) Target Setting
A target setting facility by which the user could select up to six primary and six secondary targets and a desired time point or span;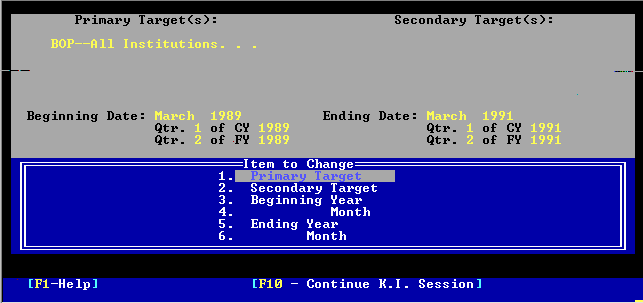
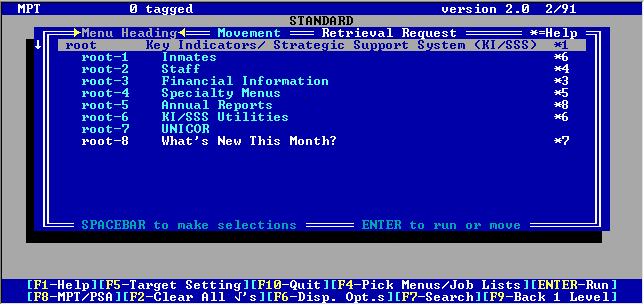
2) Retrieval Selection
A retrieval selection facility (referred to as the "main menu") which allowed the user to select prewritten retrival programs;
3) Text Display
A text display and print facility for viewing and printing text output.
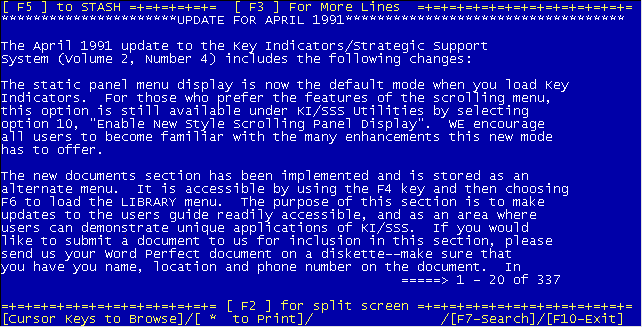
Graphics
Graphic output was presented directly by the PRODAS xygraph module. Graph printing was initially handled by a commercial utility called Graphprint but later versions used a pascal based graphic display and print routine, which reduced the cost of each new site by $50.Growing Pains
The initial pilot for the system was initiated in mid 1989, running on the newly available 16 Mhz 386 PC's with 30 MB removable hard disk drives produced by Tandon. Pilot sites were responsible for their own equipment acquisitions. Before the pilot ended in 1990, the system was stretching the limits of the newer 60 MB Tandon drives. The pilot had originally been planned to last a year and provide monthly updates to a dozen sites. By the end of six months, the total had grown to nearly three times that number. Before the end of the first twelve months, the pilot was up to sixty locations due solely to demands for equal access by FBOP administrators.
Demise of the Tandon Data-Pac
The task of rotating the disk packs in and out of the office and doing individual updates was becoming overwhelming, so a new approach was needed. CD-ROM was just becoming a mainstream item, the High Sierra standard was in the process of being formalized into ISO 9660. Individual readers were available for less than $800. By placing the system on CD-ROM discs, no recycling would be necessary. The cost for distribution via overnight express would also be greatly reduced due to the difference in the weight of the media (1 ounce per site vs 4 pounds).
In early 1990, a local Meridian Data office produced two "proof of concept" discs for us, using their cd recordable writer (a $10,000 item at the time, with media running $25 each). The discs were merely CD based images of the current 60 MB Tandon Datapac, but they offered physical proof to the BOP administration that it was a feasible approach.
Setting Up for CD-ROM
Following a demonstration for the Director of the FBOP, the ORE was given the go ahead to pursue in-house pre-mastering, to acquire CD readers for all current KI/SSS sites, and to enter into an agreements with a mastering facility to produce monthly updates on a year by year basis. We initally used a Meridian Data CD Publisher system, consisting of their Datamax cabinet equipped with four 300 MB ESDI drives (later expanded by the addition of two 600 MB drives) driven by SCSI - ESDI adaptors , and attached to an 8mm Exabyte tape unit. This was controlled by Meridian's multi-mode drivers (providing on the fly configuration of DOS and High Sierra volumes) and CD publisher software which provided for real time CD emulation for performance testing. This was installed onto a 20 Mhz Northgate 386 fitted with a Western Digital 7000 FASST SCSI adaptor.
We produced our first mass replicated CD in June of 1990. It incorporated mouse support for menu item access. This release of the system was labeled as KI/SSS version 2.x (CD + Mouse)
Adapting to CD-ROM
One of the things that was noticed early on was the need to optimize retrievals to compensate for the mediocre performance of the early CD readers. We had already gone to use of a ram-disk for storing the run time copies of the interface, PRODAS software, the current retrieval program, and temporary data files. The ramdrive approach reduced the original factsheet generation time from 150 seconds to 30 seconds. The improvement was because of the burden that had imposed by constant loading and reloading of PRODAS components from the hard drive.Single time point queries did well enough when run from the CD, but multiple time point requests, such as monthly admissions across a four year period, could take ages to generate. The problem was that the program had to query the index for each target time point, get the data, then query for the next time point, etc. The reads from different areas on the CD could end up taking nearly a second per data point. With six targets across fortyeight months, this could result in waits of almost five minutes for a table or chart!
This situation prompted the creation of a number of utility programs in TP that PRODAS could call via an EXTERNAL statement. These externals took advantage of the PRODAS dataset structure to return blocks of records in a single data access. As a result, charts and tables like the one described never took more than a minute, even on the original machines using the early CD readers.
The TurboVision Interface - As Good as DOS Gets
Improvements in Borland's products permitted similar improvements in KI/SSS interface design. In 1993, the KI/SSS version 3.x DOS interface was developed to make use of Borland's TurboVision application framework. Produced initially using TV version 6 and was later converted to TV version 7 (TurboVision version numbers were synched to the current Turbo Pascal version).
Main Menu
The TurboVision framework provided a consistant look and feel across the KI/SSS modules that was similar to the more sophistocated applications of the period. It provided both pull down and pop-up menus, and a 3-D control effects with shadowed buttons and windows, and fully supported mouse based interactions. It provided a look and feel very similar to the later Windows applications, but within a text based DOS environment.
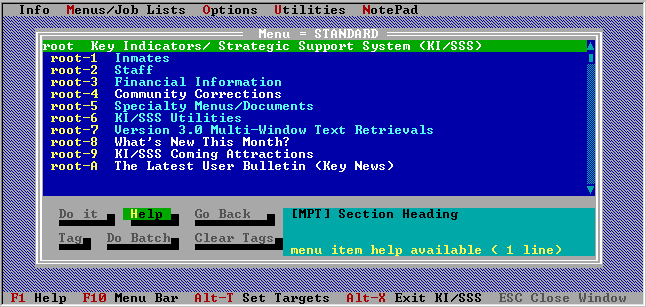
Text Display
Under the TV framework, the text display module was enhanced to provide for highlighting and hyper-links for helps and supporting documents. It was also modified to allow for multiple child windows within the main application window. These sub-windows provided the simultaneous display of mutiple documents, or multiple views into a single document. Users could select a locked scroll mode that would permit them to maintain a synchronized view across multiple documents, where each document represented the same information display for a different target location.

Target Setting
The target setting mechanism was simplified somewhat replacing some on screen selection mechanisms with popup dialogs.

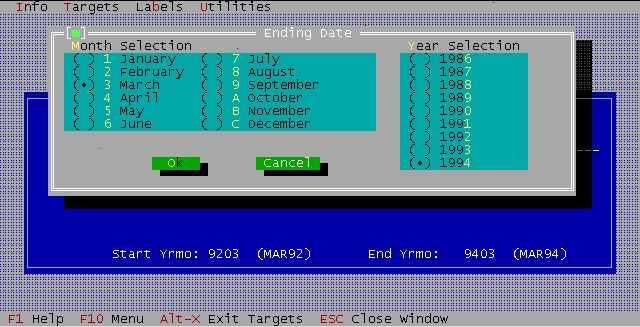
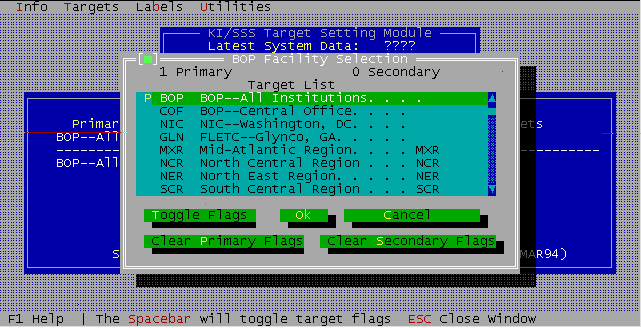
The version 3.2 KI/SSS user interface provided functionality both for the DOS environment and the increasingly more popular Windows 3.x environment. Its DOS based TurboVision framework served as the major underlying mechanism for KI/SSS user interface development until late 1995, when replaced by Windows based development under Borland's Delphi product.
Conversion to Detailed Facility Code Links (DFCL) and Type of DFCL Code (TODCODE)
In October 1996, Key Indicators moved from use of IIS codes for institution target keys to the use of the Sentry based Detailed Facility descriptors. Previously, institutions were identified by a three digit numeric that had been associated the the old Inmate Information System (IIS) and Continuous Actions File (CAF). The IIS system had been non-functional for a number of years, the CAF function had been absorbed into Sentry, and new numbers were being added in an unacceptably adhoc fashion. Additionally, there were mission categories within institutions defined by Sentry which could provide for a more detailed view of institution operations.Consequently, all KI/SSS data structures were translated to use keys based on the Sentry type of DFCL coding. Essentially, this involves a three character mnemonic followed by one or more type of DFCL flags. The result is referred to as a TODCODE. Aggregations above the institituion level are designated by strings of numeric characters. This ensures a sort sequence in which the aggregate records appear first.
Goodbye to the RAM Drive
In November 1996, a new KI/SSS installation utility was released that permitted users to install Key Indicators without having to define a RAM drive in their config.sys file. By this point in time, equipment performance had reduced the benefit to be found in the use of a RAM drive for housing temporary work space. This change made installation of Key Indicators a much easier process for the technically challenged.Conversion to PRODAS 4.0
In January of 1997, KI/SSS converted from PRODAS version 3.2 to PRODAS version 4.0. A national upgrade was purchased by the Office of Research to cover all existing KI/SSS users. Although discussed on a number of occassions as a mechanism to conserve storage space, conversion to version 4.0 was primarily undertaken to overcome compatibility problems with version 3.2 and Windows 95.Version 4.0 permitted use of a greater number of data types than 3.2, which permitted more efficient data storage. There were also benefits in terms of the potential length of field identifiers and labels. Version 4.0 also had a more extensive macro capability than did 3.2. Some modifications were required to make all current retrievals compatible with the new version, but in-house written search and replace utilities handled better than 95% of all needed changes. The version number for KI/SSS went from 3.1 to 3.2 as a result of this update.
Windows and Borland's Delphi Product
In mid 1995, Borland introduced it's Delphi product, which was quickly acquired as a development tool by the Office of Research. It was initially published as a 16 bit, Windows 95 compatible, Rapid Application Development (RAD) environment and took the place of the Object Windows Library (OWL) that had been part of the Borland Professional Pascal product. Delphi was a natural for developing a native windows user interface for Key Indicators related products. Because Delphi was based on the Object Pascal language that had evolved from Turbo Pascal, existing support code could readily be incorporated into this new environment. A number of interactive data exploration tools were produced prior to the creation of a new Key Indicators user interface, including outlier detection, ESMI presentations, and Prison Social Climate Survey exploration tools.Several 16 bit Delphi based KI/SSS interface prototypes were developed and tested within the Office of Research for use under both Windows 3.1 and Windows 95. In early 1997 a final version was constructed using a 32 bit Delphi environment, and made available for controlled testing and use within the office as a Windows 95 only product.
In November 1997, users were first given open access to the Windows 95 version of the KI/SSS user interface. As a transitional phase, both the DOS based interface (version 3.2) and and the Windows based interface (version 4.1.0) were distributed on the same CD for one year. The last CD issued with version 3.2 of KI/SSS was October, 1998.
The Windows 95 version incorporated HTML formatted text. Document generation utilities had been developed to easily produce tables and factsheets using table specifications, factsheet templates and PRODAS datafiles. By November of 1998, KI/SSS graphics were being stored as Windows Metafiles rather than HPGL files (although Metafile exports had been available all along). This was the point in time when an in-house graphics utility producing native Windows Metafile output was introduced into use.
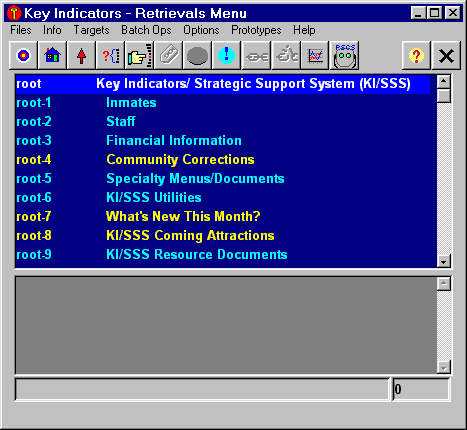
Version 4 of KI/SSS maintained some similarity with the visual layout characteristics of version 3, but was clearly a native Windows product with a strong graphics emphasis. The "Main Menu" module retained the hierarchical menu structure, but now incorporated speed buttons for quick access to common operations.
KI/SSS version 4 Main Menu
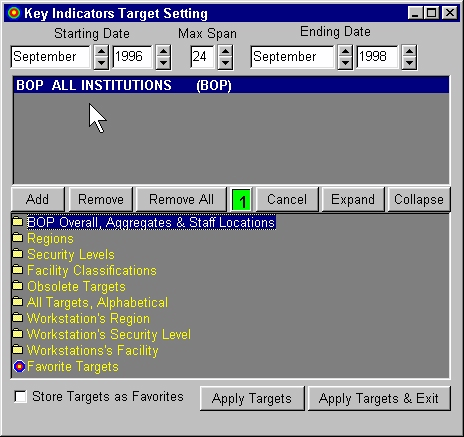
KI/SSS version 4 Target Setting (original)
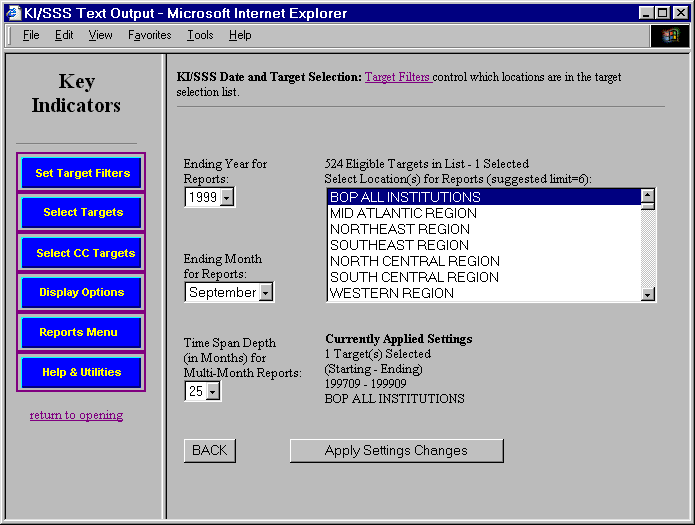
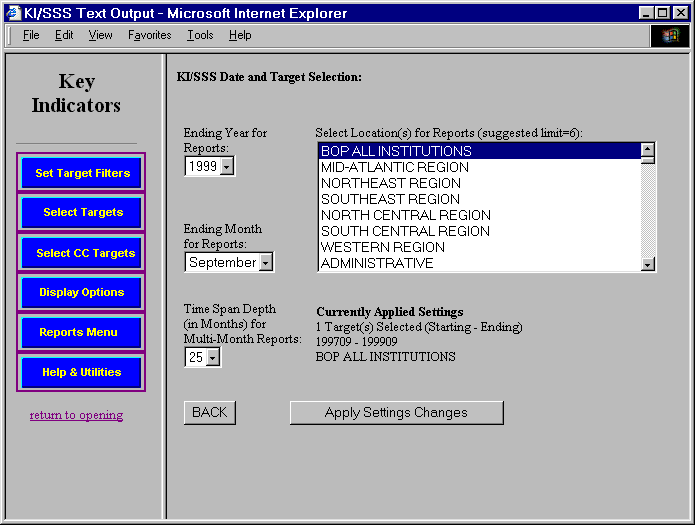
The target setting module originally made use of a folders approach to organizing the increasing number of target locations.
KI/SSS version 4 Target Setting (later)
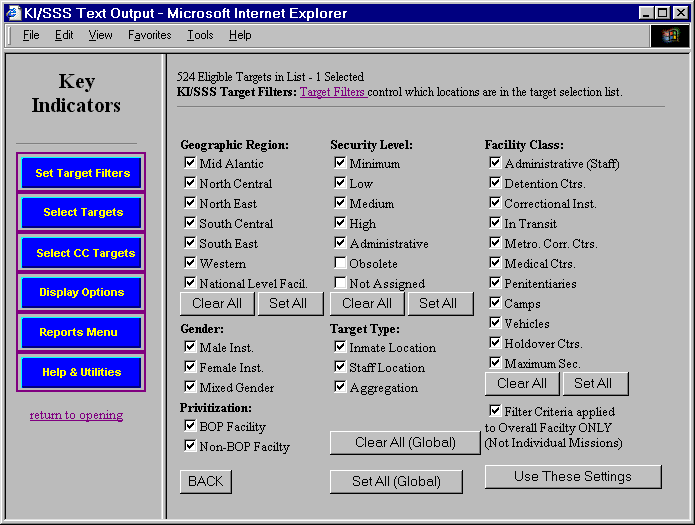
As the number of targets increased, and the types of queries became more involved, it became necessary to provide a mechanism for "filtering" the target list to a more managable number of items. In June of 1999, this was done by providing the user a way to constrain the items which would appear on the list.
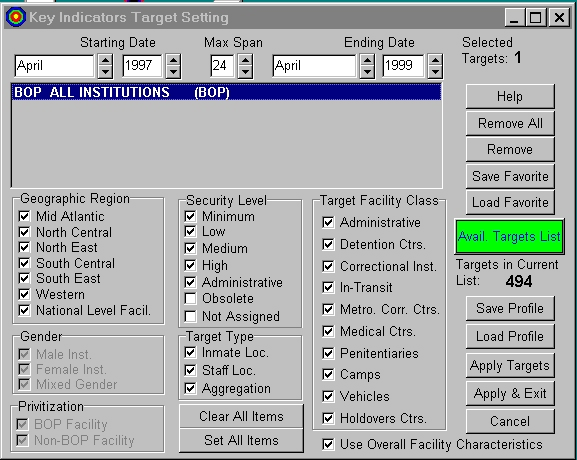
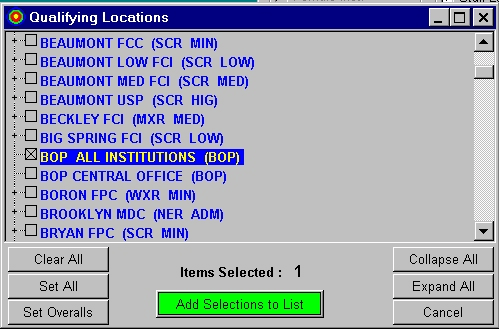
KI/SSS version 4 Filtered Target List
The target list would be limited to those characteristics checked on the filter list.
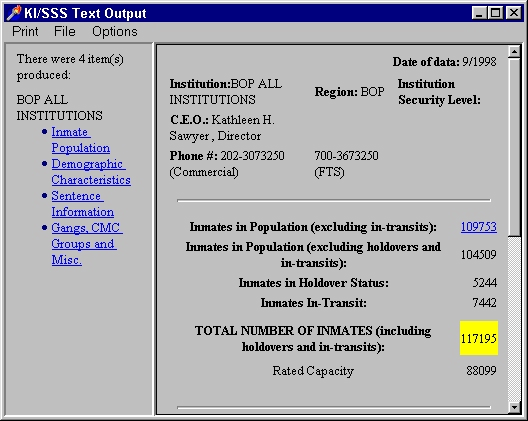
Presently, all KI/SSS output is being generated as HTML documents. Graphic output, although initially generated as HPGL graphics, are stored as using the Windows Metafile format (.WMF). These changes have made incorporation of KI/SSS output into word processing documents a pretty straight forward process.
KI/SSS version 4 Text Display
The KI/SSS version 4 text display is, essentially, a frames capable HTML browser with some specializations to support KI/SSS document handling.
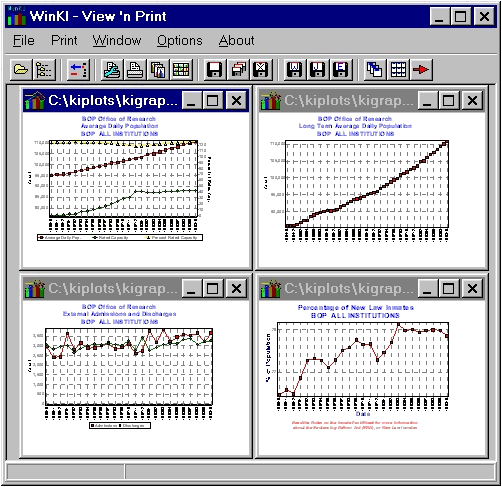
KI/SSS version 4 Graphic Display
The KI/SSS version 4 graphic display is a windows metafile viewer/printer, handling standard (.WMF) and enhanced (.EMF) metafiles. Multiple graphics can be viewed and printed at the same time, with an option to put multiple images on a single page of output.
1999 A National Site License for PRODAS
The continuing use of DOS based PRODAS was beginning to be problematic. The difficulty was primarily due to an incompatibility with Windows NT based workstations. Negotiations with Conceptual Software ensued to attempt secure the developement of a native windows version of PRODAS that would be compatible in all windows environments. Eventually it was decided that the windows based DBMSCOPY package would be enhanced to run existing PRODAS program code, and that the BOP would secure a national site license, in perpetuity, for the use of that product in conjunction with Key Indicators.
The license was worded to provide use of both the existing PRODAS 4.0 environment and the DBMSCopy Analyst package, with updates and fixes supplied as part of an annual maintainance agreement. The site license agreement made it possible to open up access to Key Indicators to all BOP personnel and affiliates, without the need for license compliance monitoring.
Early in the development process, Conceptual Software isolated and corrected the Windows NT incompatibility within PRODAS 4.0, which provided more breathing time on the conversion to DBMSCopy Analyst.
Key Indicators for the BOP Intranet
Capacity on the CD has been an issue from 1998 on. A band-aid fix involved converting data files from PRODAS version 3.2 format to version 4.0 in order to take advantage of datatype that were more economical in their storage requirements. This provided some temporary relief, but there was no question that we would eventually need to trim time points from the datasets. Although this would be unnoticed by the vast majority of users, the idea of losing widespread access to any data was unpleasant. A number of alternative methods were examined that would permit continued bureau wide access to data not placed on the CD-ROM. The main problem with using the BOP WAN for such access involved the need for user's to log in to a given piece of equipment to gain access to the additional data. The BOP's move to "IP to the desk top" in late 1999, and the planed expansion of the BOP intranet provided a viable alternative - a webserver.
Getting Started
In mid November 1999, I started work on webserver version of Key Indicators. The idea was to use the same data and PRODAS retrieval code from the CD based system to provide retrievals via a standard web browser like Netscape or Internet Explorer. The data would eventually be a superset of the CD-ROM data, including items that had been trimmed from the CD to conserve space. I had never done a web server extension, but had a number of potential tools available for doing the job in Delphi. I could either work with Href's WebHub environment, or use the native Delphi 5 components for ISAPI and CGI development. WebHub offered the potential for seamless scalability to multiple machines, but at the price of a steep learning curve and idiosyncratic architecture and syntax.
I decided to do my self-education in the simpler environment and opted for building a native Delphi ISAPI dll that would take the place of the operations normally performed by the KI/SSS user interface modules. If later testing indicated that a single machine couldn't handle the load, the application could be rewritten using WebHub to provide for greater scalability. In that case, hopefully, the experience gained in producing the first version would help flatten the learning curve.
In addition to scalability issues, there were several major considerations that had to be addressed in building the KI/SSS web server:
Adapting for Multiple Simultaneous Users
The first trick was adapting a single user application to a multiuser environment. Key Indicators retrievals had always been written with the assumption that they would run in a single user PC environment. Temporary file names were hardcoded into the retrievals and it was assumed that any configuration files in the current directory were associated with the current user.The solution here was to go to a dynamically created, uniquely named, temporary directory that was a clone of the normal KI/SSS work space. This directory is created at the first user interation with the KI/SSS web server. A cookie on the user's browser tracks the directory name for the duration of the session, and expires when the browser session ends. Target settings, preferences, and products are maintained in the temporary workspace. Minor modifications to some KI/SSS utilities and a few of the retrieval programs were necessary to permit their operation in this new environment. In most cases it meant replacing a hardcoded C:\KI_WIN reference with a relative directory reference.
Getting Data to the Browser
The second trick was to intercept the normal retrieval process in a fashion that would permit the webserver to return browser compatible products. This was handled by replacing the normal user interface executables with programs that would translate and package the output rather than provide a direct user interaction on the webserver machine. With text output, this was mainly a packaging task, as text output in KI/SSS is already in an HTML format. In the case of graphics, images are translated to .JPG and .GIF formats as well as the KI/SSS standard .WMF. The graphic translator also produces an HTML document as a framework to contain the .GIF image references which are displayed by the user's browser. In addition to the product output, the translator executables produced a flag file called "jobdone.txt" which contained the name of the file to be passed to the browser as the main document. The job submitter routine also generates a .ZIP file containing all elements that make up the current retrieval product.
Portability and Maintainability
The third trick was to ensure that the system would be maintainable, that is, be able to stay in synch with the CD based product without unreasonable manual effort. This was accomplished by writing a series of update tools to do global translations as needed. The KI/SSS menu datafile is automatically converted into a series of HTML documents that contain the necessary code for movement between menu sections, display of retrieval labels, and passing of needed information to the webserver extension to permit launching of retrieval jobs. Minor changes in some retrieval programs were needed to ensure operation in both CD and webserver settings. Items requiring user interaction for passwords required changes in their retrieval type category and their basic handling of the password process. This brought them in line with the approach used in later ESMI report operations, which made password queries the responsibility of the user interface rather than the retrieval code.
To permit movement of the KI/SSS webserver between different machines during testing, supporting files such as retrieval menu documents, frame specifications, and panel templates are stored with directory and URL references as macros. An update executable is used to read information regarding a specific server from its kisssweb.ini file, then use that information to replace the macro references while copying the files from their storage area to the working area of the server.
The KI/SSS NetRunner
A working model, an ISAPI DLL, was ready by mid December 1999. Due to scheduling snafus, it was Valentine's day 2000 before it was offically presented to BOP Assistant Director Thomas Kane for the go ahead for testing with general staff access. Subsequently, KISSS.BOP.GOV became a new site on the BOP intranet on February 16, 2000. This was none too soon, as December 1999 had become the first CD-ROM to be subject to systematic time point trimming for storage conservation.
The KI/SSS NetRunner prototype uses six basic panels to take the place of the CD based system's user interface modules. These panels are accessible from buttons on a left side frame and are displayed within a right side frame: an institution target filter; institution target setting; community corrections target setting; display options; report selection menu; and help/utilities. As the user clicks on a button, the corresponding panel is displayed within the rightside frame.
The KI/SSS NetRunner Menu
KI/SSS NetRunner Institution Target Filter
KI/SSS NetRunner Institution Target Setting
KI/SSS NetRunner Community Corrections Target Setting
KI/SSS NetRunner Display Options
KI/SSS NetRunner Help / Utilities
When a retrieval runs, a new browser window is opened to display the output. The rightside is refreshed with two links: an option to re-view the generated output; and an option to access a .ZIP file containing all the components that make up the generated output.
KI/SSS NetRunner Fact Sheet Retrieval
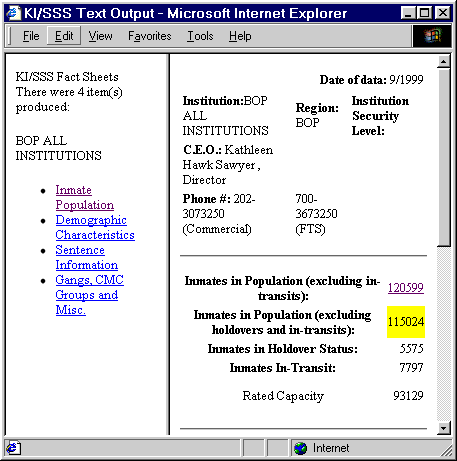
KI/SSS NetRunner Table Retrieval
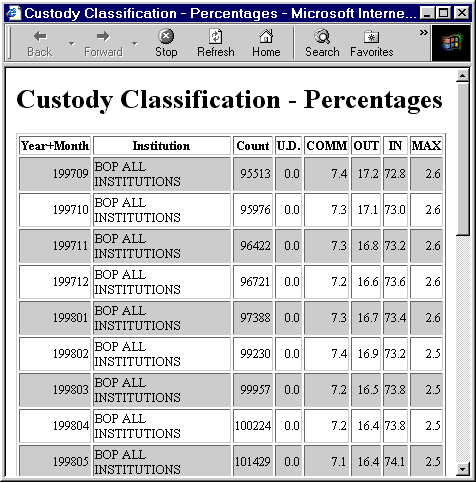
KI/SSS NetRunner Graphic Retrieval
KI/SSS NetRunner Retrieval Options
Changes last made: July 2001